Natural Language Processing with Attention Models week 1
courseraseq2seq
不定の長さの列→固定次元のベクトル→不定の長さの列、というアーキテクチャ。
- 固定次元のベクトルなので、インプットが長くなると問題になりうる
- インプットの最後の単語の方に重きが置かれる
information bottle neckというらしい。
alignment
単語の意味の曖昧さを解消すること。bank=銀行?土手?みたいな。
attention
- key, value: encoderの隠れ状態から計算される長さNのベクトル。Nはインプットの長さ
- key, valueには、それぞれに行列が付随する。これらは同じ形で、しばしば値も同じ
- query: decodeの隠れ状態から計算される
- (key, value)とqueryがattention layerに入力され、queryとkeyの内積が計算される
- その内積をsoft maxに入れて、確率分布にする
レクチャーの説明は分かりづらかった・・
Tensorflowのtutorialにも説明あり。
- key = encoderの隠れ状態
- query = decoderの隠れ状態
- keyとqueryの一致度で、入力系列全体に亘る確率分布 = 重みを作る
- 上の重みでencoderの隠れ状態を混ぜ合わせ、decoderの隠れ状態と合わせて予測値を作る
というのが大体の手順。なんでこれで精度が上がるのか良く分からない・・
以下の図は、Attentionを含んだencoder/decoderの実装の概要
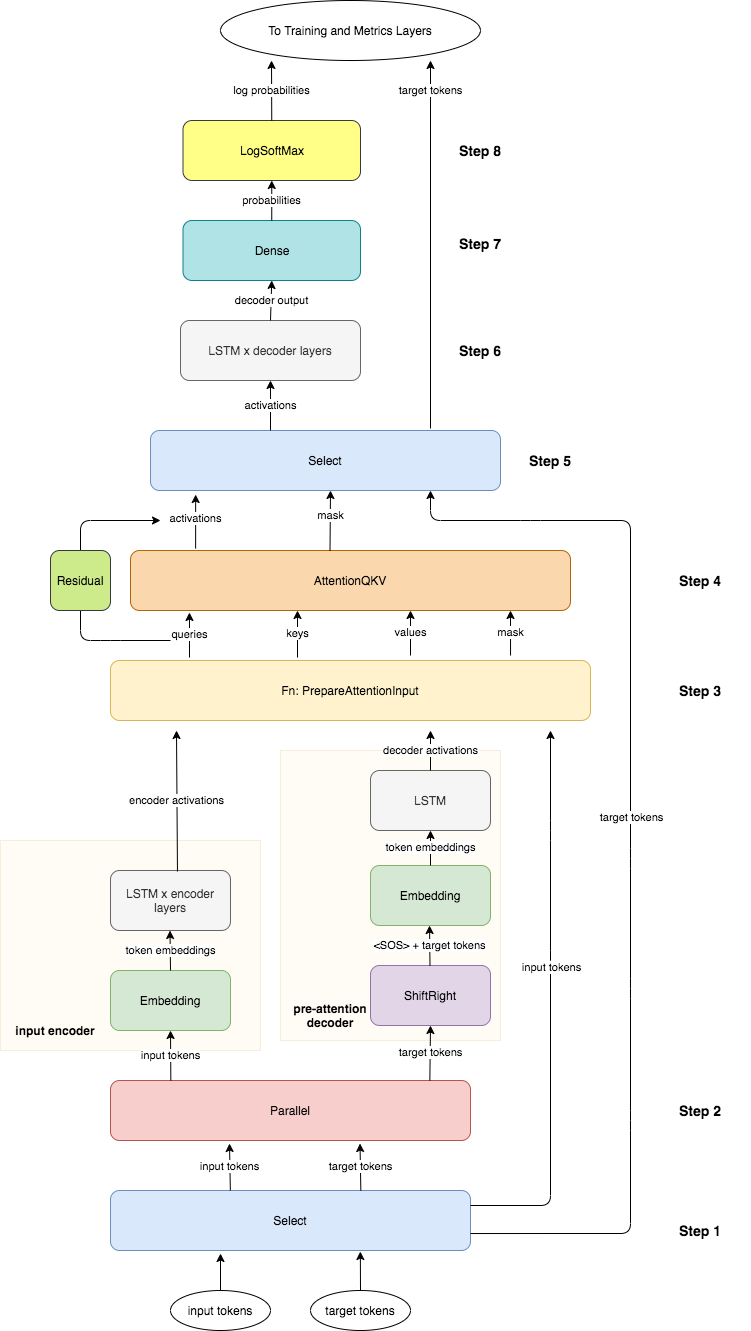
よく分かってないのは、この絵だと、入力の\(n\)単語目と出力の\(n\)単語目が同時に処理されていくように見えること。 本来は、全ての入力が処理されてから出力の1個目(=文章開始トークン)が処理されるはず。
Attentionの処理内容の意味も含めて、kerasやTFのtutorialで勉強した方が良さそう。
teacher forcing
シーケンスを出力するモデルの場合、最初の1個目で外すと、その後も外れる可能性が高く、計算が無駄になりそう。 なので、訓練時に、直前の時刻の予測値ではなく直前の時刻に対応する教師データを使うようにする。 これによって収束が早くなる。
ただし、訓練時には教師から予測する一方で、予測時には自分の予測値を使うので、訓練/予測時で 異なる挙動をし得る。こういうのをExposure biasと言うらしい。
評価指標
BLEU
bilingual evaluation understudy

- 予測文章(機会が生成した)と参照文章(人間が書いた)を比較
- 以下2つの数値の比率を評価指標とする
- 分母は、参照文章の単語数
- 分子は、予測文章中の単語の中で、参照文章中に現れる単語の数。ただし、同一単語が複数回、予測中に現れる場合、参照文での出現回数までしかカウントしない
ROUGE
Recall-Oriented Understudy for Gisting Evaluation


recall/precisionを単語やn-gramを用いて計算する。単一の指標ではなく、それらrecall/precisionの集まり。
decoding
beam saerch
良く分からなかったので、再度、勉強する。
minimum bayes risk
複数の候補文を生成し、それらの類似度を計算する(rougeなど)。自分以外の全候補文に対する類似度が最大のものを選ぶ。
dataset
opus 翻訳文のデータセット
trax
TDFSというデータロードのためのクラスがある- bucketing. 1つのバッチに入っているデータの長さを大体同じにする(paddingが少なくなる)