Natural Language Processing with Sequence Models week 3
courseraGradient Descentについて
このポスト が詳しい。
ロス関数の可視化。Filter normalizationという 手法があり、ネットワークのアーキテクチャがロス関数の形状に与える影響を見れる。 skip-connectionを導入したり、各層をwideにすることで、ロスがなめらかで凸に近くなる、らしい。
色んなモデルのロス関数を可視化したページ: https://losslandscape.com/
- global minimaにこだわる必要はない。「良い」local minimaがたくさんあることが知られている
- stochastic gradient descentは、saddle pointを回避する効果もある(サンプルによって、lossの形状が変わるから)
- learning rateのスケジュールにも色々ある
- 一定回数lossが改善しなくなったらlrを小さくする。lossが十分小さくなったら止める
- lrを小さくしたり大きくしたりするのを繰り返す
- Stochastic Weight Averaging: ランダムな初期値からの学習を数回繰り返し、予測として、それらの平均を使う
LSTM
RNNで時間方向のbackpropagationで勾配が消失することを避けるために使う。
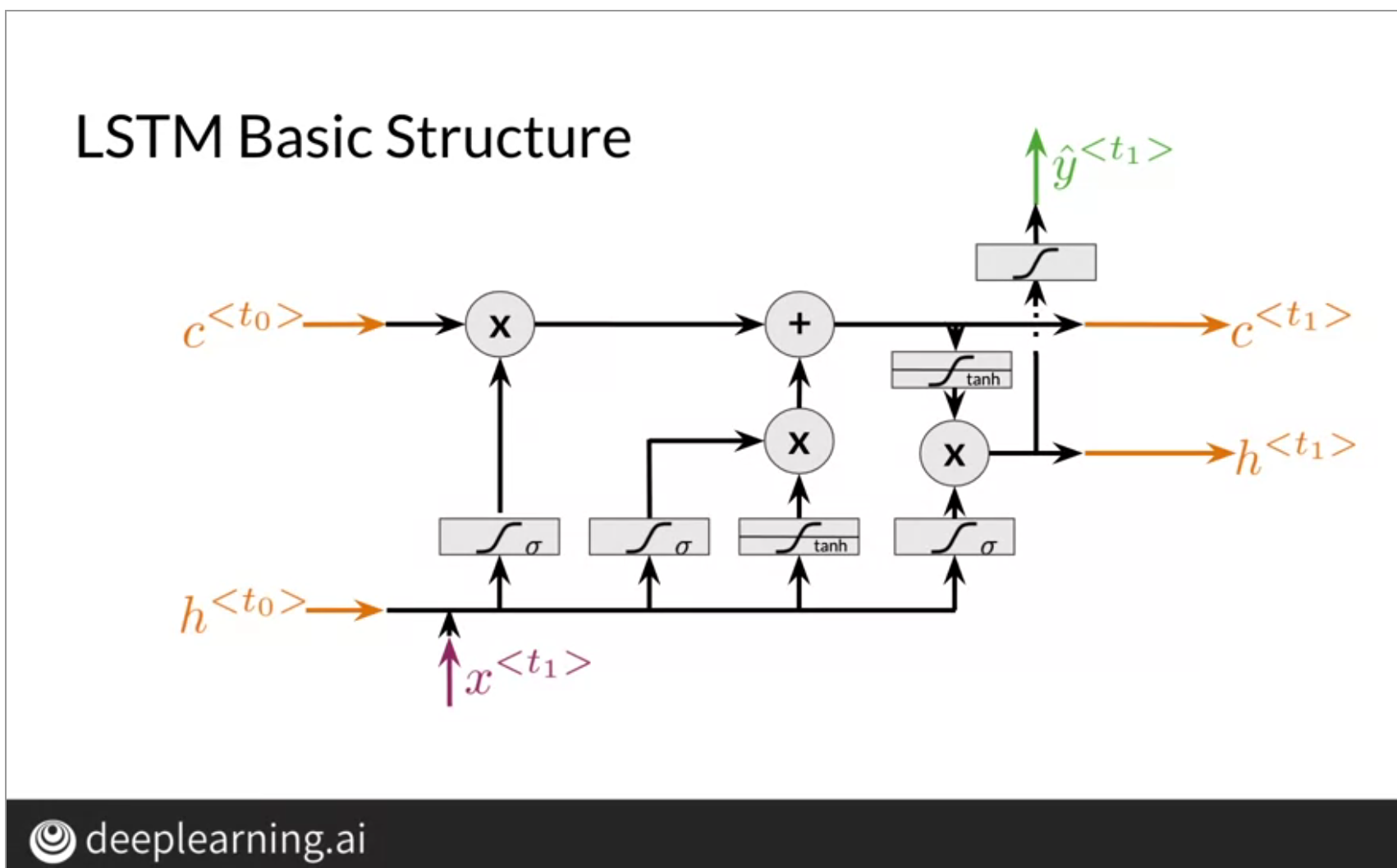
- c: cell memory
- h: hidden state
- x: 入力
- 左のシグモイド: forget gate。状態と入力から忘れるべき場所を計算
- 真ん中のシグモイドとtanh: input gate。tanhで、今回の情報を計算。シグモイドで、更新の対象を計算。
- 右のtanhとシグモイド: output gate。メモリーから次の状態を計算。